Apache Spark - Broadcast Hash Join

In this technical article, we'll discuss about one of Apache Spark's efficient join technique called Broadcast Hash Join. I will explain in detail how this operation is implemented internally in Spark at DAG(Directed Acyclic Graph) level and also different phases of DAG. We'll also uncover the details of division of spark application into jobs and stages.
Data - To explain this join concept, I'll take customer data of a hypothetical online service provider organization with international presence. Different customers across the world using its services holds accounts with this company. Moreover the customers uses different devices to access this company's website. Hence to fetch the details of different customers(business_accounts) and the corresponding device used by them, we'll use two datasets:
Business Accounts data - Data consisting of details of the customer's business account, created with this service providing organization. The schema for this dataset though consists of around 28 columns, but the key columns of interest are business's accountId, account_type, businessName, businessId, country and state.
Datasets path in S3:
I have created a dedicated bucket named spark-buckt, for these datasets in S3:
business_account = s3://spark-buckt/src/business_account/
business_device = s3://spark-buckt/src/business_device_bhj/

Lets start the learning journey.
Let us first count the records in our two data sets by creating dataframes and running a count action. I am using Zeppelin as client.
Business_account - count ~ 10 million

Business_device - count = 190000 ~ 0.2 million

Python Join code - Lets perform the join now. I am using python to code my script broadcast_hash.py and I have named my Spark application as brdcst_hsh_jn. The code is as follows:



Data - To explain this join concept, I'll take customer data of a hypothetical online service provider organization with international presence. Different customers across the world using its services holds accounts with this company. Moreover the customers uses different devices to access this company's website. Hence to fetch the details of different customers(business_accounts) and the corresponding device used by them, we'll use two datasets:
Business Accounts data - Data consisting of details of the customer's business account, created with this service providing organization. The schema for this dataset though consists of around 28 columns, but the key columns of interest are business's accountId, account_type, businessName, businessId, country and state.
Device data - This consists of the details of the device used by the customer(business), to avail the desired service. It consists of business's accountId, account_type, deviceId, date(date on which the device was used), date_last_observed, record_datetimestamp.
If you have referred my other blog on Sort Merge Join, I am using similar data. But to show you broadcast hash join, I have deliberately constructed this data of size lesser than 10 MB. This makes this join eligible for Broadcast hash join.
If you have referred my other blog on Sort Merge Join, I am using similar data. But to show you broadcast hash join, I have deliberately constructed this data of size lesser than 10 MB. This makes this join eligible for Broadcast hash join.
Problem statement - We need the business accounts and the corresponding device details for which we have to join the business accounts and device datasets on accountId. We'll perform this join and since the size of the device dataset is 9.9 MB in size and is less than 10 MB, by default this join would be executed by Spark as broadcast hash join.
Why is it so - Because the default maximum size of any table to participate in a broadcast hash join is 10 MB as shown below(for Spark v2.3.0)

Why is it so - Because the default maximum size of any table to participate in a broadcast hash join is 10 MB as shown below(for Spark v2.3.0)
Infrastructure:
Cloud provider - AWS
Cluster - EMR(v5.12.1), 5 nodes cluster of r4.8xlarge instance type.
Cluster - EMR(v5.12.1), 5 nodes cluster of r4.8xlarge instance type.
Storage - S3
NOTE - While reading this article, if any time you need better image resolution, please click on images to enlarge.
Datasets path in S3:
I have created a dedicated bucket named spark-buckt, for these datasets in S3:
business_account = s3://spark-buckt/src/business_account/
business_device = s3://spark-buckt/src/business_device_bhj/
Lets start the learning journey.
Let us first count the records in our two data sets by creating dataframes and running a count action. I am using Zeppelin as client.
Business_account - count ~ 10 million
Business_device - count = 190000 ~ 0.2 million
Python Join code - Lets perform the join now. I am using python to code my script broadcast_hash.py and I have named my Spark application as brdcst_hsh_jn. The code is as follows:
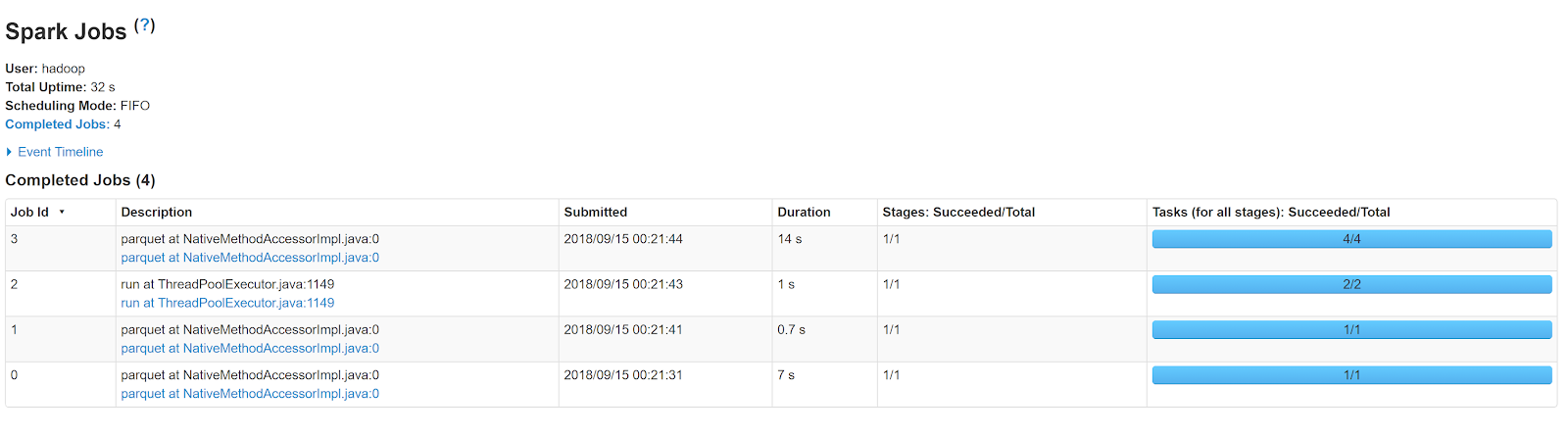
I executed this Spark application on my EMR cluster, using yarn cluster manager and utilizing dynamic allocation of resources. It executed in 32s as shown below(application name brdcst_hsh_jn):

Jobs of this Spark application:
As we can clearly see the last job - Job3 for parquet action, took most of the execution time. Lets dive into the DAG of this Job and analyze the stages:
As clearly shown above this job ran in just one stage, hence no extra shuffling of data transfer over the network. This is the benefit of Broadcast hash join. As I have explained in my previous blog on Sort Merge join, if I disable the broadcast hash join property or increase the device data's size to a value greater than 10 MB, then this would span at least 3 stages.
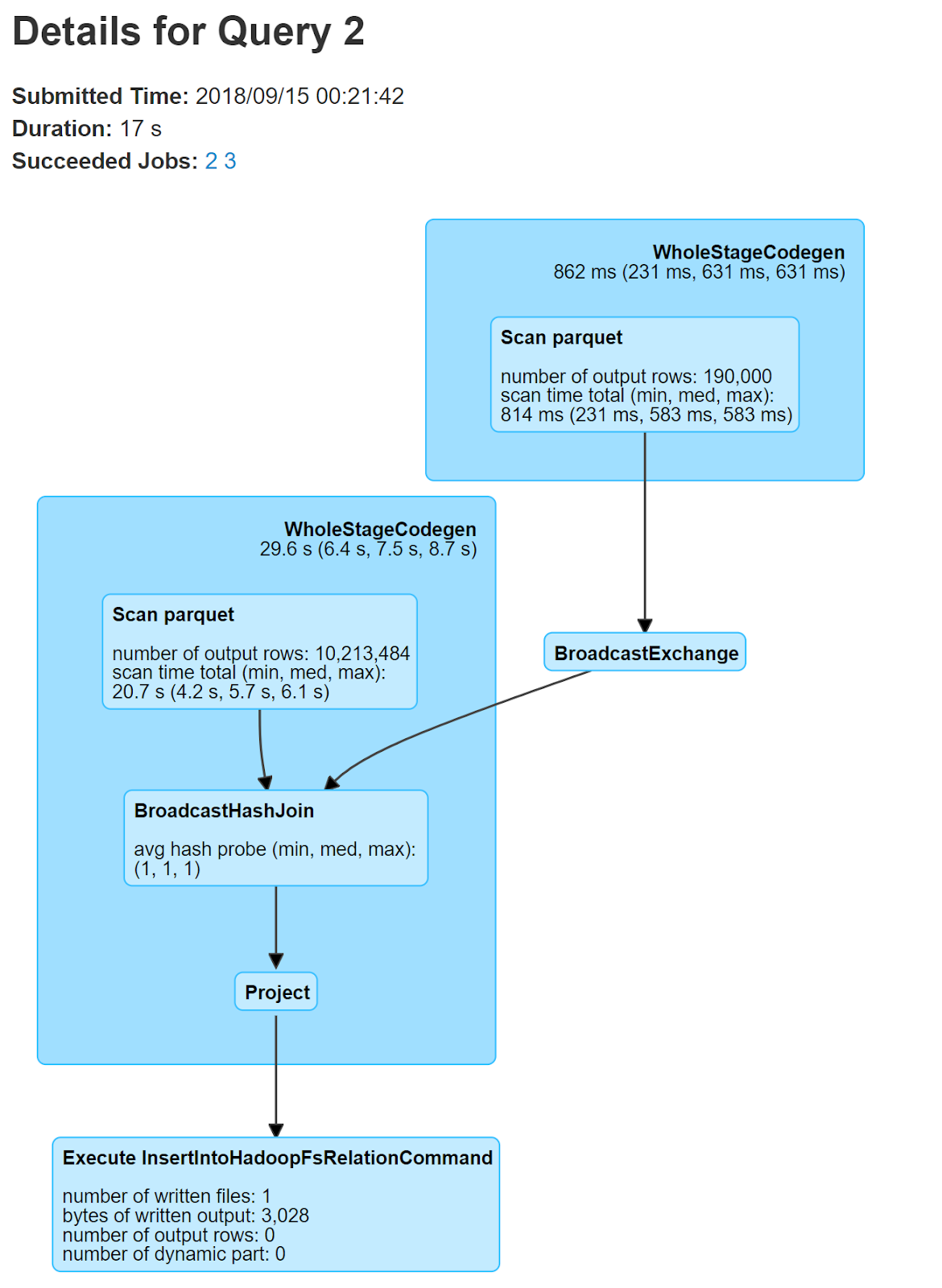
Let me explain the details of what exactly is happening in this stage by opening the query plan:
Let me explain the details of what exactly is happening in this stage by opening the query plan:
As per the core concept of Spark's broadcast hash join, the data for the two business_account and business_device data sets gets first scanned and mapped into the required key values. This happens in the Scan Parquet step. The Scan parquet from which the Broadcast exchange is coming out, is where the device(smaller) data is mapped into key vale pairs. This is clearly proved by the number of rows = 190000, which is for device data. Here the key would be the accountId.
Then in the broadcast exchange phase this device data is broadcasted onto the nodes where the business account data is existing. This is where the optimization comes as this data doesn't need to go through different stages and travel over the network and go through the time and processor heavy serialization and deserialization processes. Then in the BroadcastHashJoin phase the inner join happens and in the project phase the required output columns are projected. Finally the output data file of join result is written in parquet format to the S3 output location( as shown below)
Then in the broadcast exchange phase this device data is broadcasted onto the nodes where the business account data is existing. This is where the optimization comes as this data doesn't need to go through different stages and travel over the network and go through the time and processor heavy serialization and deserialization processes. Then in the BroadcastHashJoin phase the inner join happens and in the project phase the required output columns are projected. Finally the output data file of join result is written in parquet format to the S3 output location( as shown below)








Comments