Apache Spark - Explicit Broadcasting Optimization

Join operation is an indispensable part of majority of Big Data Projects. If you are using Apache Spark for your Big Data processing and using join operation, in this article I'll explain a strategy to optimize joins. The technique I'll explain is how to explicitly broadcast a table, in any Spark join operation and convert the join operation to Broadcast Hash Join.
Why Broadcasting - When we perform a join operation in Spark SQL, broadcasting proves very efficient in reducing data shuffling and hence serialization and deserialization of data over the network, which happens during a Sort Merge Join operation.
If you haven't read my previous article on Spark's Broadcast Hash join, I highly recommend you to first go through that. This would provide you most of the deeper details of Spark's Broadcast hash Join. You can please find it here :-
Broadcast Hash Join - By Akshay Agarwal
Business use case - To explain this optimization, let's take the business use case of an e commerce organization such as amazon.com. Let us suppose our business requirement is to fetch the details of the item or product users clicked on amazon.com. As there are millions of items shown on the website, we are interested in knowing the details of specific items users clicked on a particular day.
Why Broadcasting - When we perform a join operation in Spark SQL, broadcasting proves very efficient in reducing data shuffling and hence serialization and deserialization of data over the network, which happens during a Sort Merge Join operation.
If you haven't read my previous article on Spark's Broadcast Hash join, I highly recommend you to first go through that. This would provide you most of the deeper details of Spark's Broadcast hash Join. You can please find it here :-
Broadcast Hash Join - By Akshay Agarwal
Business use case - To explain this optimization, let's take the business use case of an e commerce organization such as amazon.com. Let us suppose our business requirement is to fetch the details of the item or product users clicked on amazon.com. As there are millions of items shown on the website, we are interested in knowing the details of specific items users clicked on a particular day.
Data - As mentioned above, we'll use click stream data of an e commerce company, such as Amazon.com. This data is specifically the one obtained when any visitor clicks on amazon.com home page, where we are shown different personalized options such as Trending Deals, New and innovative products, Recommended for you etc.
Now let us consider we have sourced the data from Adobe's Omniture system, which provides us the click id and for each click, several other attributes related to that click(in the form of Props and Evars). The click stream data provides us the item id but we also have a dimension table which consists of the details of all the items displayed.
Well this boils down to a join requirement, where we need to join the click stream data with the item dimension table on item id and thus fetch the item details.
Click data (Parquet files) - Data consisting of details of clicks on the home page by different visitors. The schema for this dataset though consists of several columns including the page section, super section etc, but the key column of interest for our use case is item_id.
Well this boils down to a join requirement, where we need to join the click stream data with the item dimension table on item id and thus fetch the item details.
Click data (Parquet files) - Data consisting of details of clicks on the home page by different visitors. The schema for this dataset though consists of several columns including the page section, super section etc, but the key column of interest for our use case is item_id.
Item data (Parquet files) - This consists of the details of the items as shown on amazon.com website, and contains all the required details including type of item, department it belongs to, cost of item, warranty etc. The key column we are interested in is the item_id which I'll join my click data on.
Infrastructure - I am using:
AWS(Amazon Web Services)
EMR Cluster(Big Data Processing Cluster)
EMR Release Label - v5.12.1
Number of Nodes - 5
Instance type - R series r4.8xlarge
Cloud storage - S3
S3 locations of datasets:
click_data = s3://spark-buckt/broadcasting/click_data/
item_data = s3://spark-buckt/broadcasting/item_data/
As my datasets are in parquet format, I'll create dataframes on top of these using spark API as follows:
Note - I am using Spark v2.3.2 and Python v2.7.15 and I am using pyspark for running transformations and actions on my data.
Click data:

Item data:
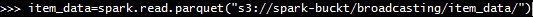
Lets first count the records in our two datasets, by executing a count action on these dataframes. As shown above, I have initiated a pyspark session on my EMR cluster's master node for this.
Counts:

Click data - counts = 82299241 records
Item data - counts = 1 million
Join without broadcasting:
item_data = s3://spark-buckt/broadcasting/item_data/
As my datasets are in parquet format, I'll create dataframes on top of these using spark API as follows:
Note - I am using Spark v2.3.2 and Python v2.7.15 and I am using pyspark for running transformations and actions on my data.
Click data:

Lets first count the records in our two datasets, by executing a count action on these dataframes. As shown above, I have initiated a pyspark session on my EMR cluster's master node for this.
Counts:
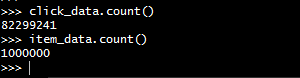
Click data - counts = 82299241 records
Item data - counts = 1 million
Now let us do a join on these two dataset and observe the Spark application's details.
Python code - File name - without_broadcasting.py. In this code I:

Lets check the Yarn application details:
Yarn Application details
This application completed in 52 sec:

When I opened the show action's job 2 from this application, it actually executed in 3 stages as follows:

- first built the spark session object named spark,
- then created the dataframes for item and click data in S3,
- then created temporary views on these dataframes, to use in my join sql transformation.
- then finally called the show action.
Lets check the Yarn application details:
Yarn Application details
This application completed in 52 sec:
When I opened the show action's job 2 from this application, it actually executed in 3 stages as follows:
It clearly shows stage 2 and stage 3 are the bottle necks which did shuffling and stage 2 took its own longest time of 24 seconds and stage 3 took 5 seconds. Lets take a look at the DAG(Directed Acyclic Graph):
DAG without Broadcasting:

Catalyst optimizer's SQL Query plan:
 As I mentioned above, we can clearly see through the DAG also that this Job executed in 3 stages starting from Stage 2 till Stage 4. And based on the basic spark concept there is always data shuffling which happens between stages. Though the stages themselves involves execution of tasks on the same partitions on the disk.
As I mentioned above, we can clearly see through the DAG also that this Job executed in 3 stages starting from Stage 2 till Stage 4. And based on the basic spark concept there is always data shuffling which happens between stages. Though the stages themselves involves execution of tasks on the same partitions on the disk.
The data for these two joining datasets was first mapped. Then the exchange phase began during which the hash partitioning on join key column item_id happened, which is then sorted and the data is shuffled and it travels over the network. The shuffled data is read in stage 4, where it is deserialized and sort merge join happens.
DAG without Broadcasting:
Catalyst optimizer's SQL Query plan:
The data for these two joining datasets was first mapped. Then the exchange phase began during which the hash partitioning on join key column item_id happened, which is then sorted and the data is shuffled and it travels over the network. The shuffled data is read in stage 4, where it is deserialized and sort merge join happens.
The execution details I explained above, can be clearly seen through the above plan.
Bottleneck in our application - The application total uptime is 52 seconds and majority of time was spent in the stages 2 and 3 -> stage 2 which took 24 seconds and stage 3 which took 6 seconds.
Question1 - Is this a bottleneck? Yes it is.
Question 2 - Can this be overcome? Yes we can optimize this by converting our join operation to broadcast hash join.
Question1 - Is this a bottleneck? Yes it is.
Question 2 - Can this be overcome? Yes we can optimize this by converting our join operation to broadcast hash join.
Join with broadcasting:
Now lets perform this same join operation by explicitly broadcasting the item dimension table as follows:
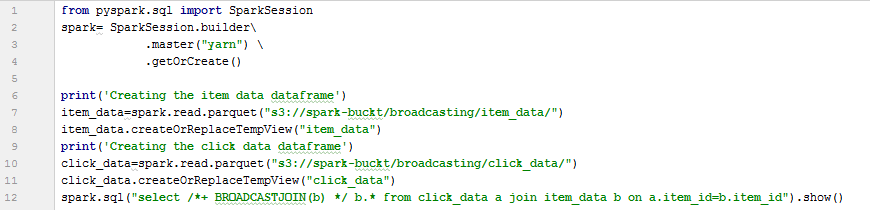
Python code - File name - with_broadcasting.py. I am repeating the dataframe and view creation steps in my code to recap things for the readers. Here one extra hint I have provided to my spark engine is the Broadcast hint to broadcast the item table.
Lets take a deeper look at the DAG of this Job:
DAG with Broadcasting:


Python code - File name - with_broadcasting.py. I am repeating the dataframe and view creation steps in my code to recap things for the readers. Here one extra hint I have provided to my spark engine is the Broadcast hint to broadcast the item table.
Lets check the Yarn application details:
Yarn Application details
This application completed in 35 sec:

When I opened the show action's job 3 of this application, it actually executed in just one stage this time as follows:

Yarn Application details
This application completed in 35 sec:
When I opened the show action's job 3 of this application, it actually executed in just one stage this time as follows:
Now this time the job kicked just one stage and that too completed in just 3 sec. Hence no extra shuffling of data and transfer over the network was required.
Lets take a deeper look at the DAG of this Job:
DAG with Broadcasting:

Catalyst optimizer's SQL Query plan:
As it can be clearly seen the join this time completed in just one stage. Now that is the best optimization that we can achieve by explicitly broadcasting our smaller item table.
As per the core concept of Spark's broadcast hash join, the data for the two click data and item data sets gets first scanned and mapped into the required key values. This happens in the Scan Parquet step. The Scan parquet from which the Broadcast exchange is coming out, is where the item(smaller) data is mapped into key vale pairs. Here the key would be the item_id.
As per the core concept of Spark's broadcast hash join, the data for the two click data and item data sets gets first scanned and mapped into the required key values. This happens in the Scan Parquet step. The Scan parquet from which the Broadcast exchange is coming out, is where the item(smaller) data is mapped into key vale pairs. Here the key would be the item_id.
Then in the broadcast exchange phase this item data is broadcasted onto the nodes where the click data is existing. This is where the optimization comes as this data doesn't need to go through different stages and travel over the network and go through the time and processor heavy serialization and deserialization process. Then in the BroadcastHashJoin phase the inner join happens and in the project phase the required output columns are projected.
I have deliberately chosen such data, in which the join happens on very few item_ids. This is to show that without broadcasting and going with the regular sort merge join, we get the shuffling between stages and shuffle write of the whole datasets, which is expensive. Whereas in case of broadcast hash join, it executed the join in just one stage, thus completely overcoming the cost of shuffling. Also this data I chose is small in magnitude, thus it gave a difference of execution in just seconds. Once we execute our join on large amount of data, we should see even more difference in duration of execution when broadcasting is done versus when it isn't done.








very nice post,keep sharing more blogs with us.
ReplyDeletebig data hadoop training
Sure Veera. Good to know that you liked it. I will be publishing more articles.
DeleteNice post. By reading your blog, i get inspired and this provides some useful information. Thank you for posting this exclusive post for our vision.
ReplyDeleteSummary Generator
Summarize Tools
Summary Tool
Summarizing Tools
Article Summarizer
Mr Akshay u have a lot of knowledge in Spark. I request please share ur knowledge and post most frequently
ReplyDeleteVenu
spark training in Hyderabad
bigdata institute in Hyderabad
https://bigdatasolutionss.blogspot.com/2019/01/limitations-of-apache-spark.html